
北京智源研究院的研究團隊近日發布了OmniGen 2,這款開源系統能夠實現文生圖、圖像編輯和上下文圖像生成。
相較于2024年11月發布的第一代,OmniGen 2采用雙路解碼架構:文本與圖像路徑擁有獨立參數,并配備解耦的圖像標記器。研究團隊表示,這種設計能在保留核心文本生成能力的同時,基于現有多模態大語言模型進行擴展。

OmniGen 2支持多種提示詞和藝術風格,但其寫實圖像仍存在輕微模糊問題 | 圖片來源:吳等人
該模型以Qwen2.5-VL-3B Transformer為多模態基座,圖像生成模塊采用約40億參數的定制擴散Transformer。當遇到特殊標記"<|img|>"時,系統會自動從文本生成切換至圖像生成模式。
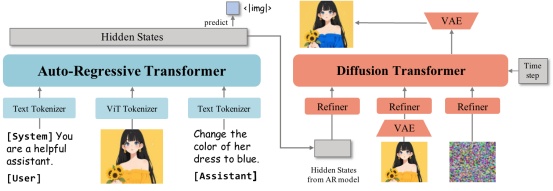
雙路解碼架構:自回歸Transformer處理文本,擴散Transformer生成圖像,兼顧語言能力與視覺質量 | 圖片來源:吳等人
訓練數據包含1.4億張開源與專有圖像。團隊還創新性地利用視頻素材——例如提取同一人臉微笑前后的幀序列,通過語言模型自動生成對應的編輯指令。

支持局部編輯而無需全圖重生成 | 圖片來源:吳等人
在上下文圖像生成方面,OmniGen 2能追蹤視頻中的人物或物體跨幀表現,從而學習同一主體在不同場景下的特征。

多圖融合生成能力 | 圖片來源:吳等人
創新性多模態位置編碼
團隊提出的"Omni-RoPE"位置嵌入技術,將位置信息分解為序列ID、模態ID和圖像元素2D坐標三重標識。這種設計使模型能精準處理多輸入源的時空組合。
獨特之處在于,OmniGen 2僅將VAE(變分自編碼器)特征作為擴散解碼器輸入,而非整合到主語言模型中。這一選擇簡化了架構,更好保留了語言理解能力。
自反思迭代優化機制
核心亮點是自反思機制:模型可評估生成圖像的質量,通過多輪迭代進行改進。系統能識別缺陷并給出具體修正方案。
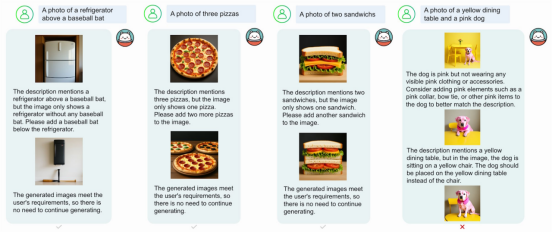
自反思機制實現圖像自動優化 | 圖片來源:吳等人
由于缺乏上下文圖像生成的權威基準,團隊推出了OmniContext評測體系,包含角色、物體、場景三大類,每類8個子任務各50個樣本。
GPT-4.1負責評估生成結果,從提示準確性和主體一致性兩個維度進行0-10分打分。OmniGen 2以7.18分超越所有開源模型,而近期新增原生圖像生成的GPT-4o得分為8.8分。
在文生圖任務中,OmniGen 2于GenEval和DPG-Bench等基準測試表現優異;圖像編輯任務上更是創下開源模型的新紀錄。
當前局限包括:英文提示效果優于中文,體型修改不夠精準,輸出質量依賴輸入圖像。對于模糊的多圖提示,需明確指定物體位置指令。
精選文章: