
加州大學默塞德分校與Adobe的最新合作,在人體圖像補全領域取得突破性進展。這項名為CompleteMe的技術不僅能修復受損圖像,還能根據參考圖像為人物"換裝",在虛擬試衣、動畫制作和照片編輯等場景展現強大潛力。

CompleteMe系統通過參考圖像(中列)為原始圖像(左列)生成自然逼真的補全效果(右列)。案例來自論文補充材料:查看詳情
這項發表于arXiv的研究采用雙U-Net架構與區域聚焦注意力模塊(RFA),通過參考圖像指導系統修復被遮擋的人體部位:

CompleteMe能精準適配參考圖像內容至目標區域
技術核心:雙網絡協同作戰
系統由兩大核心構成:
參考U-Net:處理多角度參考圖像,提取細節特征
補全U-Net:整合掩碼圖像與參考特征,生成最終結果
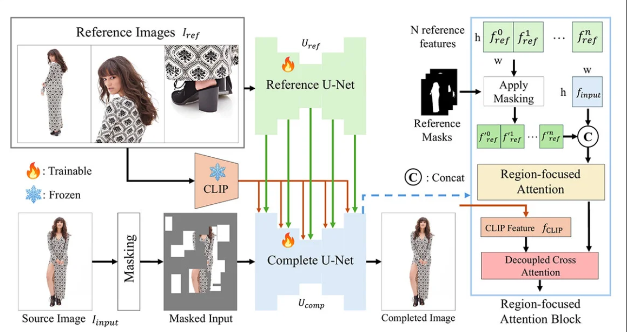
系統架構示意圖?來源
關鍵技術突破包括:
1區域聚焦注意力機制:通過空間掩碼確保模型僅關注相關區域
2CLIP語義特征融合:結合全局語義理解與局部細節特征
3復合掩碼策略:隨機網格遮擋+人體形狀掩碼組合訓練
性能碾壓現有方案
在包含417組測試數據的定制化基準上,CompleteMe在多數指標上全面領先:
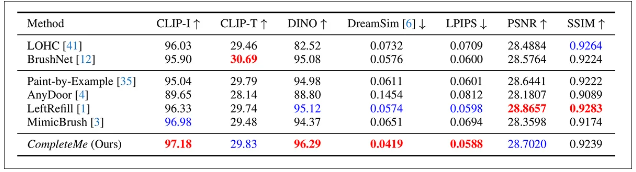
定量評估結果(數值越高越好)
用戶研究顯示,在2895組對比測試中,CompleteMe生成的圖像在視覺質量和特征保真度上獲得顯著偏好:
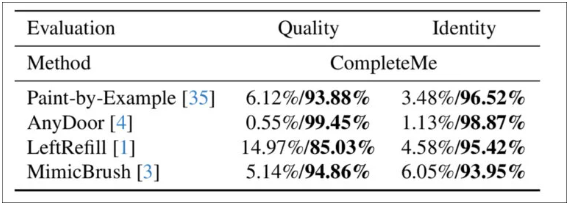
用戶調研結果
典型案例對比可見,傳統方法(紅框標注)難以還原紋身、特殊服飾等細節:

與參考基線方法對比,CompleteMe精準保留參考圖像特征
應用前景與局限
雖然項目GitHub頁面暫未開源代碼,但其在時尚領域的應用潛力已引發關注。研究人員特別指出,該系統在復雜姿勢、精細服飾等挑戰性場景表現優異。

這項研究標志著AI圖像編輯從"無中生有"邁向"按需定制"的新階段,為數字內容創作提供了更精準的工具。建議讀者深入研讀完整論文與補充材料,以全面了解技術細節。
精選文章: