
對(duì)于普通用戶而言,若想將個(gè)人形象嵌入主流AI圖像視頻生成工具,往往面臨一個(gè)現(xiàn)實(shí)門(mén)檻:除非你是家喻戶曉的公眾人物,否則必須預(yù)先通過(guò)個(gè)人照片集訓(xùn)練專屬的LoRA(低秩適應(yīng))模型。這套"數(shù)字身份證"一旦建立,生成系統(tǒng)便能在后續(xù)創(chuàng)作中精準(zhǔn)還原用戶特征。
這項(xiàng)被稱為"AI定制化"的技術(shù),其發(fā)展歷程頗具戲劇性。2022年Stable Diffusion橫空出世后不久,谷歌研究院便率先推出名為DreamBooth的閉源解決方案。這個(gè)需要數(shù)GB存儲(chǔ)空間的定制模型,很快被技術(shù)極客破解改良,最終以開(kāi)源形式回饋社區(qū)。
而LoRA模型的問(wèn)世徹底改變了游戲規(guī)則。相較于前代方案,它具有三大突破性優(yōu)勢(shì):訓(xùn)練流程大幅簡(jiǎn)化、模型體積顯著縮小、生成質(zhì)量卻分毫不減。這些特性使其迅速占領(lǐng)市場(chǎng),不僅成為Stable Diffusion系列模型的標(biāo)配,更在后續(xù)問(wèn)世的Flux等圖像模型,以及混元視頻、萬(wàn)2.1等視頻生成平臺(tái)上大放異彩。
技術(shù)迭代之痛與破局之道
我們注意到一個(gè)持續(xù)存在的行業(yè)痛點(diǎn):每當(dāng)?shù)讓幽P透碌脩艟捅仨氈匦掠?xùn)練配套LoRA。這對(duì)內(nèi)容創(chuàng)作者而言無(wú)異于噩夢(mèng)——耗費(fèi)大量資源建立的定制模型,很可能因技術(shù)升級(jí)而一夜之間淪為"數(shù)字廢鐵"。
這一困境催生了學(xué)界對(duì)"零樣本定制"技術(shù)的研究熱潮。該技術(shù)的革命性在于:用戶僅需提供少量樣本圖片,系統(tǒng)即可實(shí)時(shí)解析特征并融入生成過(guò)程,徹底跳過(guò)了傳統(tǒng)方案中繁瑣的數(shù)據(jù)準(zhǔn)備和模型訓(xùn)練環(huán)節(jié)。如圖所示,采用PuLID框架的系統(tǒng)不僅能實(shí)現(xiàn)無(wú)縫換臉,更能將人物特征與藝術(shù)風(fēng)格完美融合。

要用通用的適配器(adapter)來(lái)取代像LoRA這樣既費(fèi)時(shí)費(fèi)力又脆弱的系統(tǒng),這個(gè)想法確實(shí)很棒(也很受歡迎),但挑戰(zhàn)也不小。LoRA訓(xùn)練過(guò)程中那種對(duì)細(xì)節(jié)的極致把控和全面覆蓋,想在IP-Adapter這類"一次性"模型上復(fù)現(xiàn)可不容易——畢竟這類模型必須在沒(méi)有事先分析大量身份圖像的優(yōu)勢(shì)下,達(dá)到和LoRA同等的細(xì)節(jié)處理能力和靈活性。
?HyperLoRA
在此刻,字節(jié)跳動(dòng)新發(fā)的一篇論文很有意思——他們提出了一種能實(shí)時(shí)生成LoRA代碼的系統(tǒng),這目前在零樣本解決方案中可是獨(dú)一份。

論文指出:
"基于適配器(Adapter)的技術(shù)(如IP-Adapter)會(huì)凍結(jié)基礎(chǔ)模型的參數(shù),采用插件式架構(gòu)來(lái)實(shí)現(xiàn)零樣本推理,但在人像合成任務(wù)中,這類方法往往缺乏自然度和真實(shí)感——這個(gè)問(wèn)題不容忽視。"
"我們(字節(jié)跳動(dòng))提出了一種參數(shù)高效的自適應(yīng)生成方法HyperLoRA,通過(guò)自適應(yīng)插件網(wǎng)絡(luò)動(dòng)態(tài)生成LoRA權(quán)重,將LoRA的卓越性能與適配器方案的零樣本能力相結(jié)合。"
"經(jīng)過(guò)精心設(shè)計(jì)的網(wǎng)絡(luò)結(jié)構(gòu)和訓(xùn)練策略,我們實(shí)現(xiàn)了支持單圖/多圖輸入的零樣本個(gè)性化人像生成,在照片級(jí)真實(shí)感、還原度和可編輯性方面都表現(xiàn)出色。"
最實(shí)用的是,訓(xùn)練好的系統(tǒng)可直接兼容現(xiàn)有ControlNet,從而實(shí)現(xiàn)高度精細(xì)化的生成控制。

至于這個(gè)新系統(tǒng)最終是否會(huì)向終端用戶開(kāi)放,字節(jié)跳動(dòng)歷史來(lái)說(shuō)可能很高——他們此前就開(kāi)源了效果強(qiáng)大的口型同步框架LatentSync,最近又剛剛發(fā)布了InfiniteYou框架。
不太樂(lè)觀的是,論文中完全沒(méi)有提及開(kāi)源意向,而且復(fù)現(xiàn)這項(xiàng)研究所需的訓(xùn)練資源極其龐大,即便是技術(shù)發(fā)燒友社區(qū)想要復(fù)現(xiàn)(就像當(dāng)初對(duì)DreamBooth那樣)也將面臨巨大挑戰(zhàn)。
這篇題為《HyperLoRA:人像合成的參數(shù)高效自適應(yīng)生成》的新論文,由字節(jié)跳動(dòng)及其旗下智能創(chuàng)作部門(mén)的七位研究者完成。
技術(shù)方案
這種新方法以Stable Diffusion的潛在擴(kuò)散模型(LDM)SDXL為基礎(chǔ)模型,不過(guò)其原理似乎適用于各類擴(kuò)散模型(但考慮到訓(xùn)練要求——詳見(jiàn)下文——可能難以應(yīng)用于視頻生成模型)。
HyperLoRA的訓(xùn)練過(guò)程分為三個(gè)階段,每個(gè)階段都旨在分離并保留學(xué)習(xí)權(quán)重中的特定信息。這種分階段訓(xùn)練的設(shè)計(jì)目標(biāo),是在確保快速穩(wěn)定收斂的同時(shí),防止身份特征被服裝、背景等無(wú)關(guān)元素干擾。
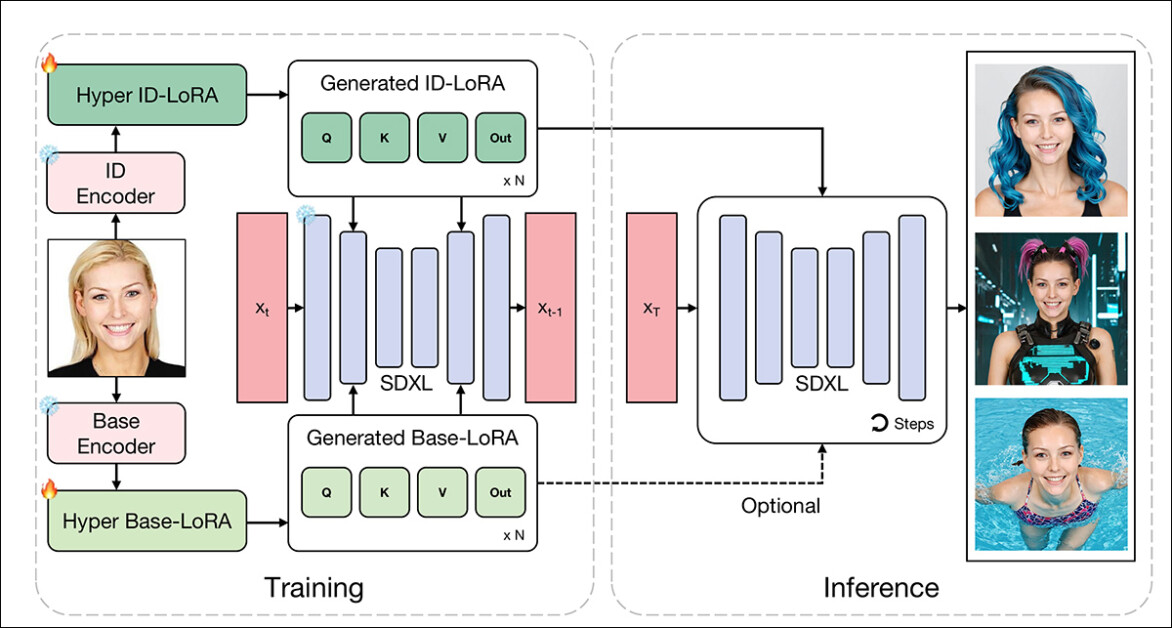
第一階段完全專注于學(xué)習(xí)"基礎(chǔ)LoRA"(示意圖左下方模塊),該模塊專門(mén)捕捉與身份無(wú)關(guān)的細(xì)節(jié)。
為確保這種分離效果,研究人員刻意對(duì)訓(xùn)練圖像中的人臉進(jìn)行模糊處理,迫使模型只能學(xué)習(xí)背景、光線和姿勢(shì)等特征——而非身份信息。這個(gè)"預(yù)熱階段"相當(dāng)于過(guò)濾器,在進(jìn)入身份特征學(xué)習(xí)前先排除低級(jí)干擾。
第二階段則引入"身份LoRA"(示意圖左上方模塊),通過(guò)雙通道架構(gòu)編碼面部特征:
CLIP視覺(jué)變換器(CLIP ViT)提取結(jié)構(gòu)特征
InsightFace AntelopeV2編碼器生成抽象身份表征
轉(zhuǎn)型方法
CLIP特征能加速模型收斂,但存在過(guò)擬合風(fēng)險(xiǎn);而Antelope表征更穩(wěn)定但訓(xùn)練較慢。因此系統(tǒng)初期主要依賴CLIP特征,隨后逐步引入Antelope,以此保持訓(xùn)練穩(wěn)定性。
最終階段會(huì)完全凍結(jié)CLIP引導(dǎo)的注意力層,僅保留與AntelopeV2連接的注意力模塊繼續(xù)訓(xùn)練。這種設(shè)計(jì)既能讓模型持續(xù)優(yōu)化身份特征保存能力,又不會(huì)破壞已學(xué)習(xí)組件的精確度和泛化性。
這種分階段架構(gòu)本質(zhì)上是特征解耦的嘗試——先將身份與非身份特征分離,再各自獨(dú)立優(yōu)化。它系統(tǒng)性地解決了個(gè)性化建模的常見(jiàn)問(wèn)題:身份特征漂移、編輯靈活性不足,以及對(duì)非關(guān)鍵特征的過(guò)擬合。
動(dòng)態(tài)權(quán)重生成機(jī)制
當(dāng)CLIP ViT和AntelopeV2從人像中分別提取出結(jié)構(gòu)特征和身份特征后,這些特征會(huì)被送入感知重采樣器(源自IP-Adapter項(xiàng)目)——這是一個(gè)基于Transformer的模塊,能將特征映射為一組緊湊系數(shù)。
系統(tǒng)采用兩個(gè)獨(dú)立的重采樣器:
基礎(chǔ)LoRA權(quán)重采樣器:編碼背景等非身份特征
身份LoRA權(quán)重采樣器:專注面部身份特征
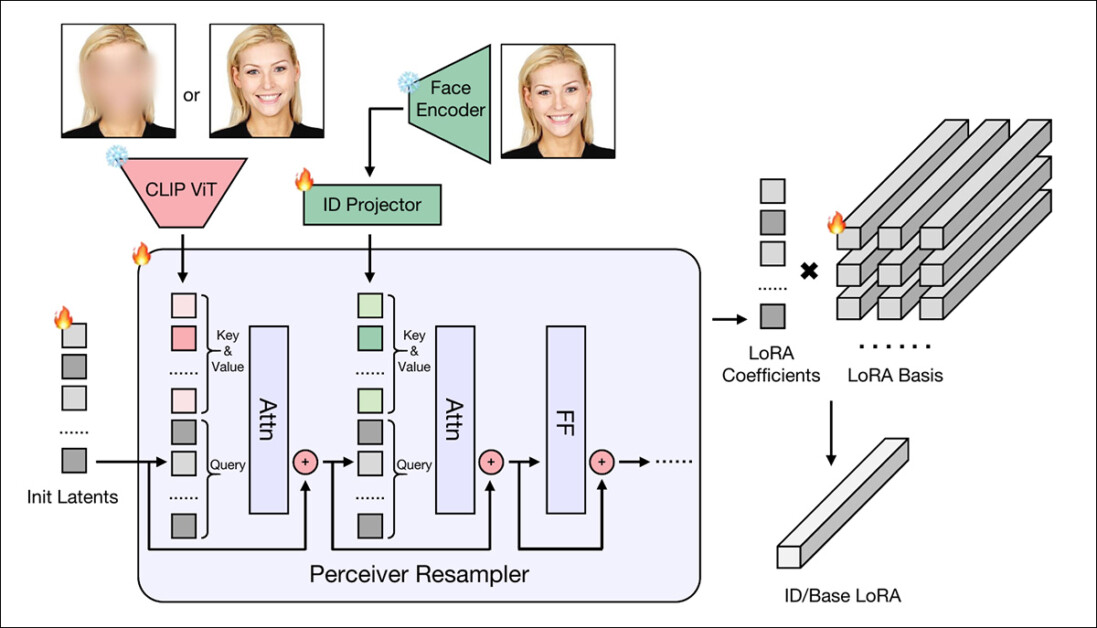
隨后,這些輸出系數(shù)會(huì)與一組預(yù)訓(xùn)練的LoRA基矩陣進(jìn)行線性組合,無(wú)需微調(diào)基礎(chǔ)模型就能生成完整的LoRA權(quán)重。
這種方法僅需圖像編碼器和輕量級(jí)投影運(yùn)算,就能實(shí)時(shí)生成個(gè)性化權(quán)重,同時(shí)充分發(fā)揮LoRA直接調(diào)控基礎(chǔ)模型行為的優(yōu)勢(shì)。
數(shù)據(jù)和測(cè)試
為訓(xùn)練HyperLoRA,研究團(tuán)隊(duì)從LAION-2B數(shù)據(jù)集中選取了440萬(wàn)張人臉圖像子集(該數(shù)據(jù)集正是2022年原始Stable Diffusion模型的訓(xùn)練數(shù)據(jù)來(lái)源)。
通過(guò)InsightFace篩選剔除非人像及重復(fù)圖像后,所有圖片均使用BLIP-2系統(tǒng)自動(dòng)標(biāo)注。在數(shù)據(jù)增強(qiáng)環(huán)節(jié),研究人員采用隨機(jī)面部區(qū)域裁剪策略,始終確保圖像聚焦人臉特征。
由于受限于訓(xùn)練硬件內(nèi)存,各LoRA模塊的秩(rank)需動(dòng)態(tài)調(diào)整:
? 身份LoRA(ID-LoRA)秩設(shè)為8
? 基礎(chǔ)LoRA(Base-LoRA)秩設(shè)為4
? 同時(shí)采用八步梯度累積來(lái)模擬更大批次的訓(xùn)練效果
具體訓(xùn)練安排如下:
? 1基礎(chǔ)LoRA模塊:20,000次迭代
? 2身份LoRA(CLIP分支):15,000次迭代
? 3身份LoRA(特征嵌入分支):55,000次迭代
? 在身份LoRA訓(xùn)練階段,系統(tǒng)按0.9/0.05/0.05的概率采樣三種條件組合
整個(gè)系統(tǒng)基于PyTorch和Diffusers框架實(shí)現(xiàn),在16塊NVIDIA A100顯卡上耗時(shí)約十天完成訓(xùn)練(640GB或1280GB的VRAM,具體取決于使用的型號(hào))。
ComfyUI 測(cè)試
研究者在ComfyUI合成平臺(tái)中構(gòu)建了工作流程,將HyperLoRA與三種競(jìng)爭(zhēng)方法進(jìn)行對(duì)比:InstantID、前文提到的IP-Adapter(具體采用IP-Adapter-FaceID-Portrait框架)以及上述引用的PuLID。所有框架測(cè)試均使用相同的初始種子、提示詞和采樣方法以確保一致性。
作者指出,基于Adapter(而非LoRA)的方法通常需要更低的分類器自由引導(dǎo)(CFG)比例尺度,而LoRA方法(包括HyperLoRA)在這方面更具靈活性。因此為了公平比較,研究者在測(cè)試中統(tǒng)一使用了開(kāi)源SDXL微調(diào)檢查點(diǎn)變體LEOSAM的Hello World模型。定量測(cè)試則采用了Unsplash-50圖像數(shù)據(jù)集作為基準(zhǔn)。
指標(biāo)
在保真度基準(zhǔn)測(cè)試中,研究者采用兩種指標(biāo)衡量面部相似度:一是通過(guò)CLIP圖像嵌入(CLIP-I)計(jì)算余弦距離,二是通過(guò)訓(xùn)練階段未使用的CurricularFace模型提取獨(dú)立身份嵌入(ID Sim)進(jìn)行比對(duì)。測(cè)試時(shí),每種方法為每個(gè)身份生成四張高清肖像,最終取平均值作為結(jié)果。
編輯能力評(píng)估則采用雙重標(biāo)準(zhǔn):一方面比較啟用與禁用身份模塊時(shí)的CLIP-I得分差異,以此衡量身份約束對(duì)圖像的改變程度;另一方面通過(guò)十組涵蓋發(fā)型、配飾、服裝和背景的提示詞變體,檢測(cè)CLIP圖文對(duì)齊度(CLIP-T)。實(shí)驗(yàn)還將Arc2Face基礎(chǔ)模型納入對(duì)比,該基線模型采用固定描述文本和裁剪面部區(qū)域進(jìn)行訓(xùn)練。
針對(duì)HyperLoRA特別測(cè)試了兩個(gè)變體:僅使用ID-LoRA模塊的版本,以及同時(shí)使用ID-LoRA與權(quán)重設(shè)為0.4的Base-LoRA的復(fù)合版本。測(cè)試發(fā)現(xiàn)Base-LoRA雖能提升保真度,但會(huì)輕微限制編輯靈活性。
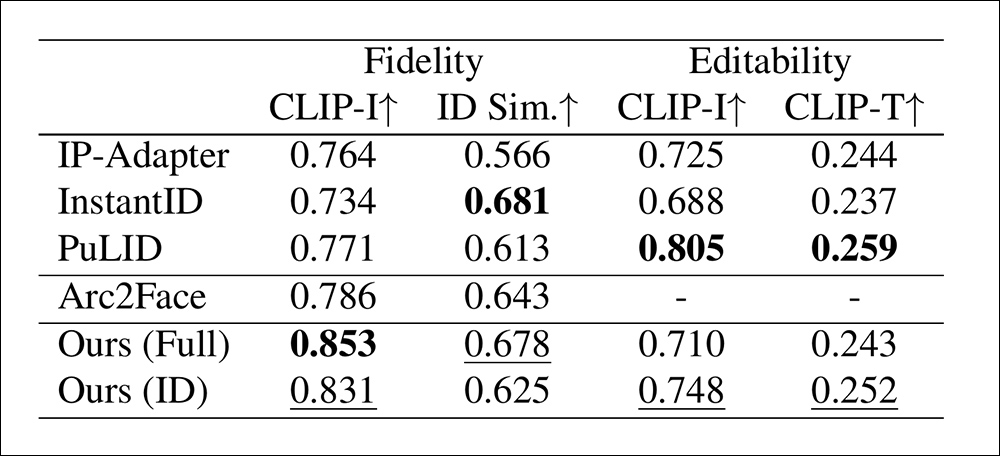
在定量測(cè)試結(jié)果分析中,研究者指出:
"基礎(chǔ)LoRA模塊雖能提升圖像保真度,但會(huì)限制編輯靈活性。盡管我們的設(shè)計(jì)已將圖像特征解耦至不同LoRA模塊,仍難以完全避免特征泄漏。因此可通過(guò)調(diào)節(jié)基礎(chǔ)LoRA權(quán)重來(lái)適配不同應(yīng)用場(chǎng)景。"
"HyperLoRA完整版與純ID版分別占據(jù)面部保真度指標(biāo)第一、二位,而InstantID在身份相似度上表現(xiàn)優(yōu)異但保真度較低。評(píng)估時(shí)需綜合考量這兩個(gè)指標(biāo)——身份相似度反映抽象特征,而保真度則呈現(xiàn)細(xì)節(jié)表現(xiàn)。"
定性測(cè)試結(jié)果(受篇幅限制無(wú)法展示全部高清對(duì)比圖像,詳見(jiàn)原文圖示)清晰展現(xiàn)了不同方法的核心權(quán)衡關(guān)系:

研究者特別指出:
"IP-Adapter和InstantID生成的肖像皮膚存在明顯AI紋理,存在[色彩過(guò)飽和]問(wèn)題,與真實(shí)照片相去甚遠(yuǎn)。這是基于Adapter方法的通病。PuLID通過(guò)減弱對(duì)基礎(chǔ)模型的侵入性改善了這個(gè)問(wèn)題,雖優(yōu)于前兩者但仍存在模糊和細(xì)節(jié)缺失。"
"相比之下,LoRA直接修改基礎(chǔ)模型權(quán)重而非引入額外注意力模塊,通常能生成高度細(xì)膩的逼真圖像。"
作者強(qiáng)調(diào),HyperLoRA直接調(diào)整基礎(chǔ)模型權(quán)重的特性,使其保留了傳統(tǒng)LoRA方法的非線性表達(dá)能力,在保真度方面具有優(yōu)勢(shì),能更好地捕捉瞳孔顏色等細(xì)微特征。定性對(duì)比顯示,HyperLoRA的畫(huà)面構(gòu)圖不僅比InstantID和IP-Adapter更符合提示詞要求(后兩者時(shí)常出現(xiàn)構(gòu)圖不自然或偏離提示的情況),其連貫性也與PuLID相當(dāng)。

結(jié)論
過(guò)去18個(gè)月層出不窮的"單樣本定制"系統(tǒng),已然顯露出某種技術(shù)焦慮——這些方案大多未能顯著推進(jìn)技術(shù)前沿,即便偶有突破,也往往伴隨著驚人的訓(xùn)練成本,或面臨極其復(fù)雜、資源密集的推理需求。
盡管HyperLoRA的訓(xùn)練規(guī)模與近期同類研究一樣令人咋舌,但至少其最終產(chǎn)出的模型能夠?qū)崿F(xiàn)開(kāi)箱即用的即時(shí)定制。根據(jù)論文補(bǔ)充材料,HyperLoRA的推理速度優(yōu)于IP-Adapter,但遜于另外兩種對(duì)比方法。需要說(shuō)明的是,這些測(cè)試數(shù)據(jù)基于NVIDIA V100專業(yè)顯卡(其32GB顯存上限雖已被新款消費(fèi)級(jí)顯卡超越,但仍非典型家用設(shè)備)。

可以公允地說(shuō),從實(shí)際應(yīng)用角度來(lái)看,零樣本定制仍是一個(gè)未解的難題——HyperLoRA雖然表現(xiàn)出色,但其苛刻的硬件需求與構(gòu)建長(zhǎng)期通用基礎(chǔ)模型的目標(biāo)存在著根本性矛盾。
精選文章:
35536塊“金磚”砌成的上海新地標(biāo),土到窒息還是有錢(qián)任性?
優(yōu)雅的現(xiàn)代奢華臥室設(shè)計(jì):打造精致外觀的小技巧
大作洗眼 | DOGUE雜志寵物封面、超前戶外廣告…定義新浪漫!